
Deep Skill Chaining
Akhil Bagaria
May 18, 2020
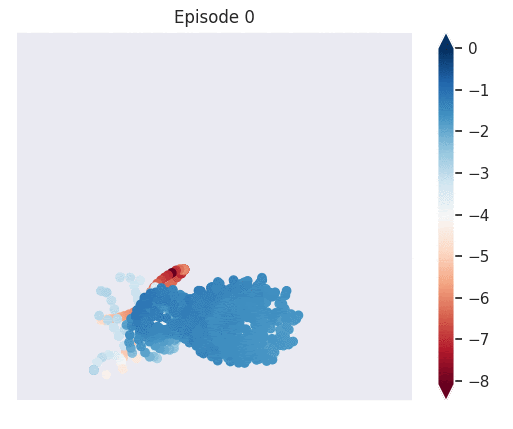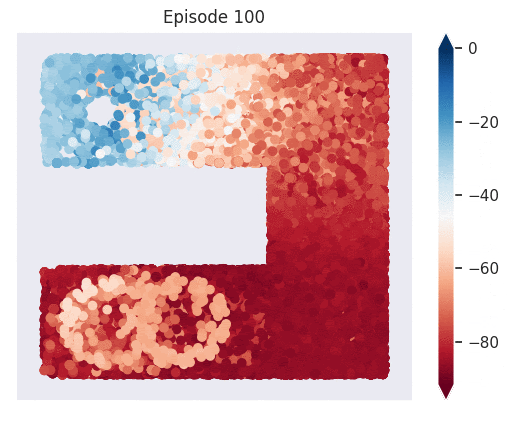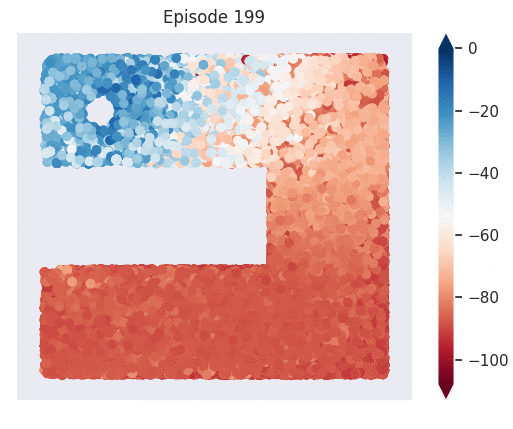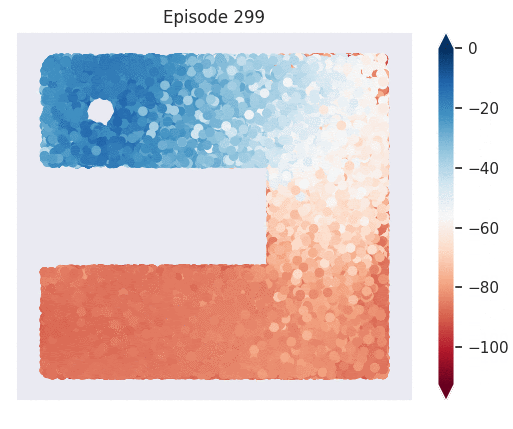
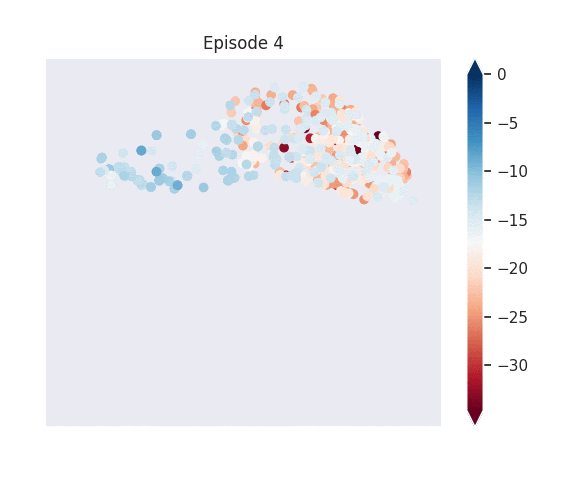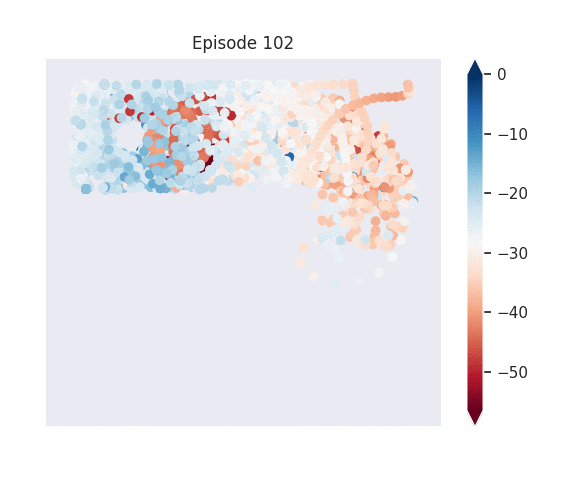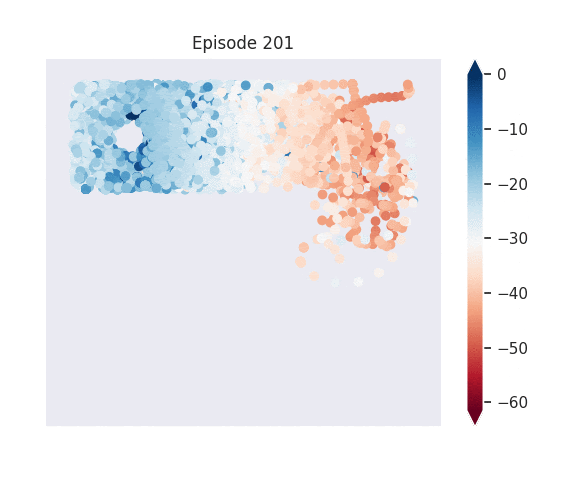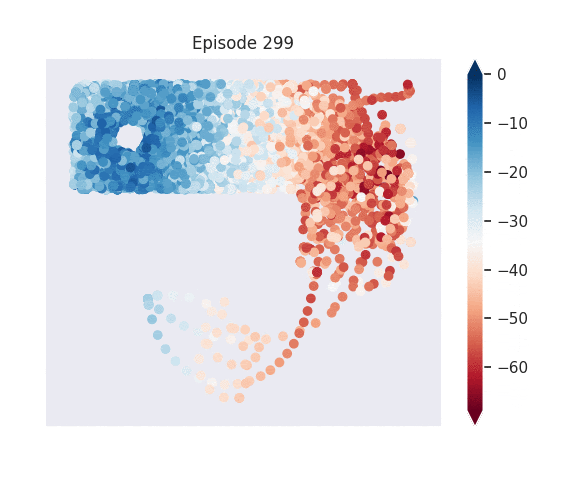
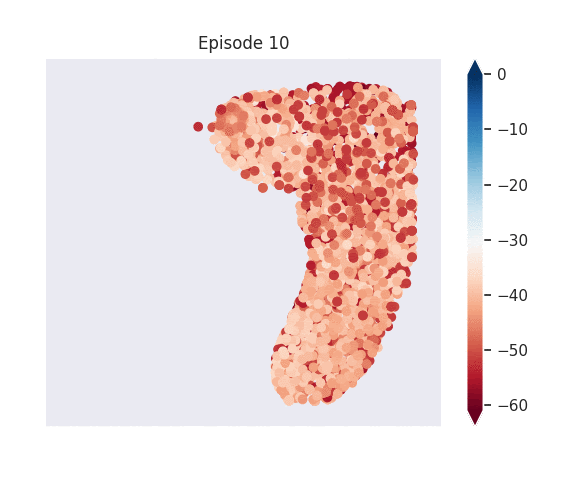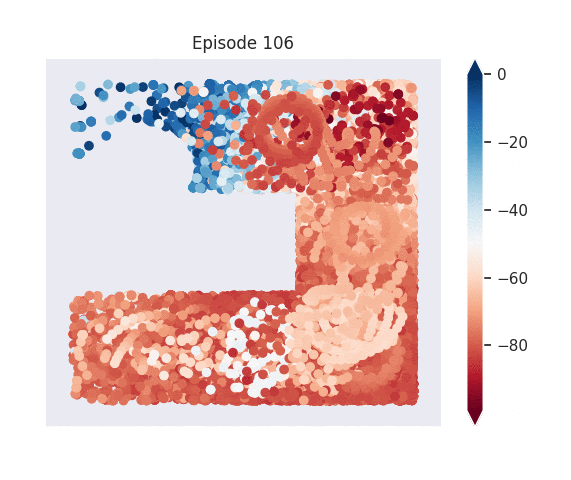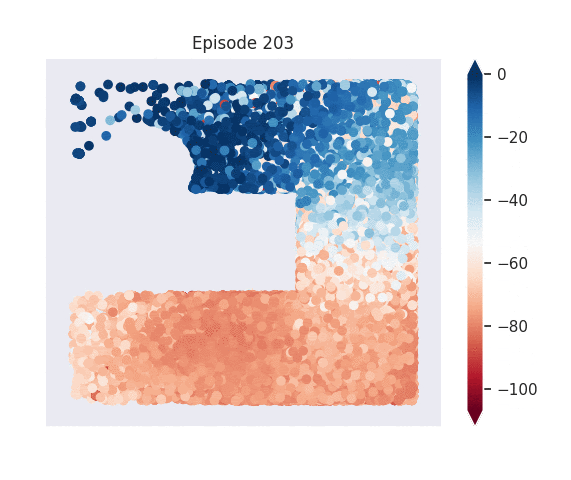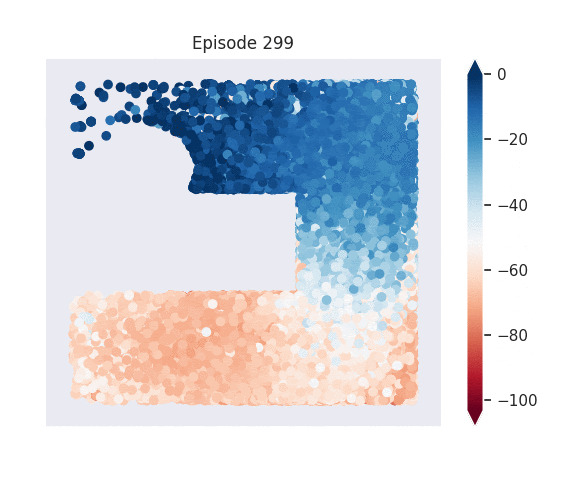
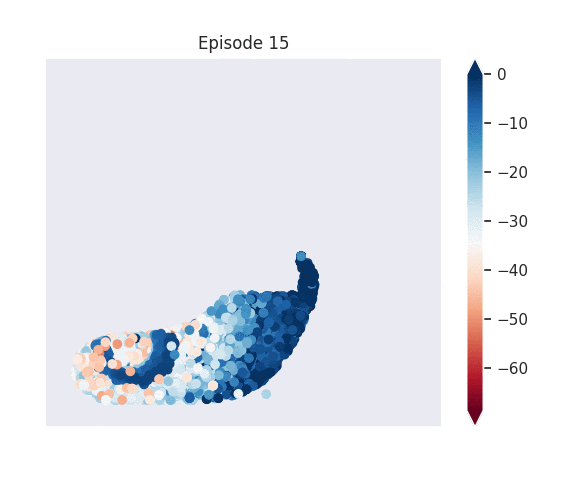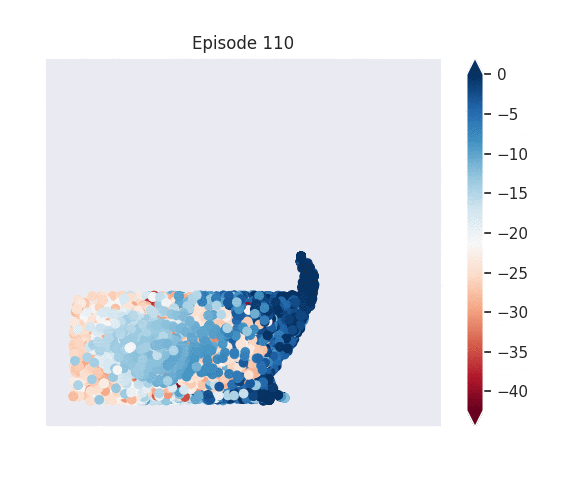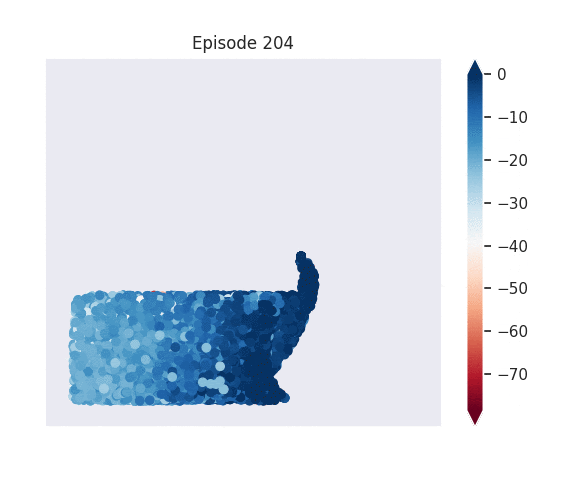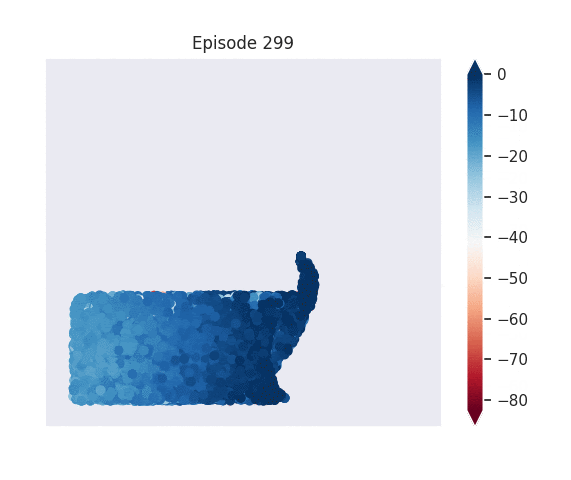 Figure 1: [Top] Combined value function learned by deep skill chaining. [Bottom] Value functions learned by discovered skills. In this U-shaped maze, the goal state is in the top-left and the start state is in the bottom-left
Figure 1: [Top] Combined value function learned by deep skill chaining. [Bottom] Value functions learned by discovered skills. In this U-shaped maze, the goal state is in the top-left and the start state is in the bottom-left
While modern RL algorithms have achieved impressive results on hard problems, they have struggled in long-horizon problems with sparse rewards. Hierarchical reinforcement learning is a promising approach to overcome these challenges.
While the benefit of using hierarchies has been known for a long time, the question of how useful hierarchies can be discovered autonomously has remained largely unanswered. In this work, we present an algorithm that can construct temporally extended, higher level actions (called skills) from the set of primitive actions already available to the RL agent.
Not only is the ability to break down complex problems into simpler sub-problems a hallmark of intelligence, it is also the missing piece from traditional/flat reinforcement learning techniques. By constructing useful hierarchies, RL agents will be able to combine modular solutions to easy sub-problems to reliably solve hard real-world problems.
We propose Deep Skill Chaining as a step towards realizing the goal of autonomous skill discovery in high-dimensional problems with continuous state and action spaces.
To learn more, see the full blog post, read the ICLR paper, or check out the code.
Learning to Generalize Kinematic Models to Novel Objects
Ben Abbatematteo
November 4, 2019

Objects with articulated parts are ubiquitous in household tasks. Putting items in a drawer, opening a door, and retrieving a frosty beverage from a refrigerator are just a few examples of the tasks we’d like our domestic robots to be capable of. However, this is a difficult problem for today’s robots: refrigerators, for example, come in different shapes, sizes, and colors, are in different locations, etc, so control policies trained on individual objects do not readily generalize to new instances of the same class.
Humans, on the other hand, learn to manipulate household objects with remarkable efficiency. As a child, we learn to interact with our refrigerator, then readily manipulate the refrigerators we encounter in the houses of our friends and relatives. This is because humans recognize the underlying task structure: these objects almost always consist of the same kinds of parts, despite looking a bit different each time. In order for our robots to achieve generalizable manipulation, they require similar priors. This post details our recent work towards this end, training robots to generalize kinematic models to novel objects. After identifying kinematic structures for many examples of an object class, our model learns to predict kinematic model parameters, articulated pose, and object geometry for novel instances of that class, ultimately enabling manipulation from only a handful of observations of a static object.
Learning Multi-Level Hierarchies with Hindsight
Andrew Levy
September 4, 2019
Hierarchical Reinforcement Learning (HRL) has the potential to accelerate learning in sequential decision making tasks like the inverted pendulum domain shown in Figure 1 where the agent needs to learn a sequence of joint torques to balance the pendulum. HRL methods can accelerate learning because they enable agents to break down a task that may require a relatively long sequence of decisions into a set of subtasks that only require short sequences of decisions. HRL methods enable agents to decompose problems into simpler subproblems because HRL approaches train agents to learn multiple levels of policies that each specialize in making decisions at different time scales. Figure 1 shows an example of how hierarchy can shorten the lengths of the sequences of actions that an agent needs to learn. While a non-hierarchical agent (left side of Figure 1) must learn the full sequence of joint torques needed to swing up and balance the pole, a task that is often prohibitively difficult to learn, the 2-level agent (right side of Figure 1) only needs to learn relatively short sequences. The high-level of the agent only needs to learn a sequence of subgoals (purple cubes) to achieve the task goal (yellow cube), and the low-level of the agent only needs to learn the sequences of joint torques to achieve each subgoal.

Figure 1: Video compares the actions sequences that need to be learned by a non-hierarchical agent (left) and a 2-level hierarchical agent (right) in order to complete the task. While the non-hierarchical agent needs to learn the full sequence of joint torques that move the agent from its initial state to the goal state (i.e., yellow cube), the 2-level agent only needs to learn relatively short sequences of decisions. The high-level of the agent just needs to learn the short sequence of subgoals (i.e., purple cubes) needed to achieve the goal. The low-level only needs to learn the short sequences of joint torques needed to achieve each subgoal (i.e., purple cube).
DeepMellow - Removing the Need for Target Networks in Deep Q-Learning
Seungchan Kim
August 12, 2019
In this paper, we proposed an approach to remove the need for a target network from Deep Q-learning. Our DeepMellow algorithm, the combination of Mellowmax operator and DQN, can learn stably without a target network when tuned with specific temperature parameter ω. We proved novel theoretical properties (convexity, monotonic increase, and overestimation bias reduction) of Mellowmax operator, and empirically showed that Mellowmax operator can obviate the need for a target network in multiple domains.
To learn more, see the full blog post, or read the IJCAI paper.